Un guide complet pour l’analyse de survie en Python, partie 3

Par Pratik Shukla, ingénieur en apprentissage automatique en herbe.
Index de la série
Partie 1:
(1) Bases de l’analyse de survie.
Partie 2:
(2) Théorie de l’ajustement de Kaplan-Meier avec un exemple.
(3) Théorie des ajusteurs de Nelson-Aalen avec un exemple.
Partie 3:
(4) Ajusteur Kaplan-Meier basé sur différents groupes.
(5) Test Log-Rank avec un exemple.
(6) Régression de Cox avec un exemple.
Dans l’article précédent, nous avons vu comment nous pouvions analyser la probabilité de survie des patients. Mais il est très important pour nous de savoir quel facteur affecte le plus la survie. Donc, dans cet article, nous discutons de l’estimateur Kaplan-Meier basé sur divers groupes.
Exemple 3: Estimateur Kaplan-Meier avec groupes
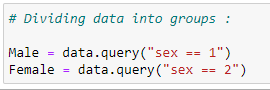
Divisons nos données en deux groupes: hommes et femmes. Notre objectif ici est de vérifier s’il existe une différence significative dans le taux de survie si nous divisons notre ensemble de données en fonction du sexe.
(1) Importez les bibliothèques requises:
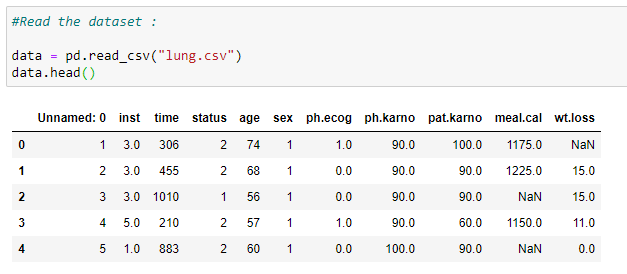
(2) Lisez le jeu de données:
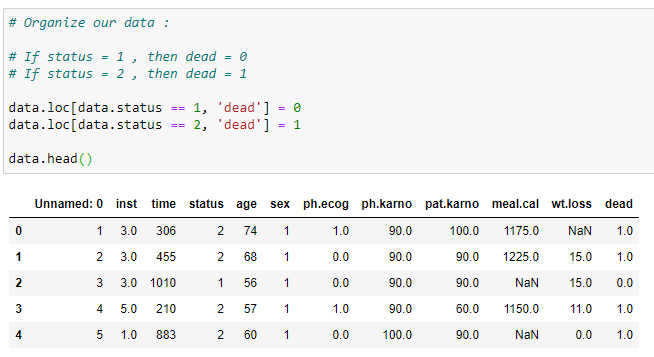
(3) Organiser nos données:
(4) Créez deux objets de KaplanMeierFitter ():
kmf_m est pour l’ensemble de données masculin.
kmf_f est pour l’ensemble de données féminin.
(5) Divisez les données en groupes:
(6) Ajuster les données dans nos objets:

(7) Générer des tables_événements:
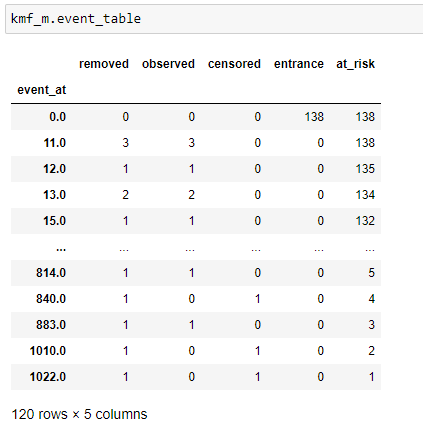
Tableau des événements pour homme.
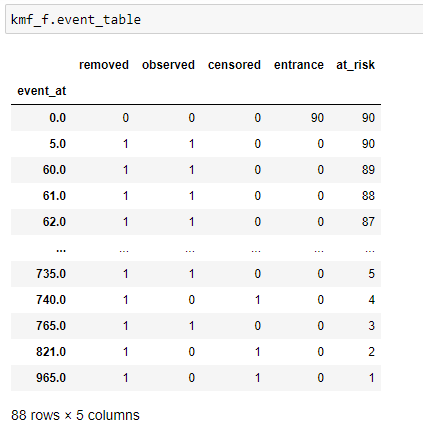
Tableau des événements pour les femmes.
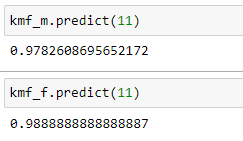
(7) Prédire les probabilités de survie:
Nous pouvons maintenant prédire la probabilité de survie pour les deux groupes.
(8) Obtenez la liste complète de survival_probability:
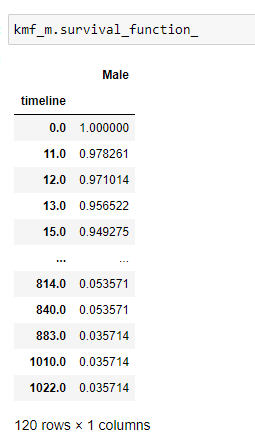
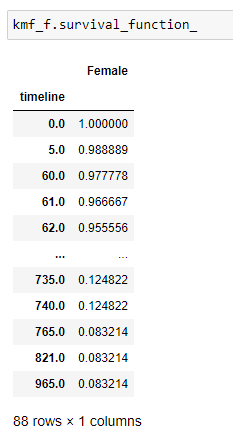
(9) Tracez le graphique:
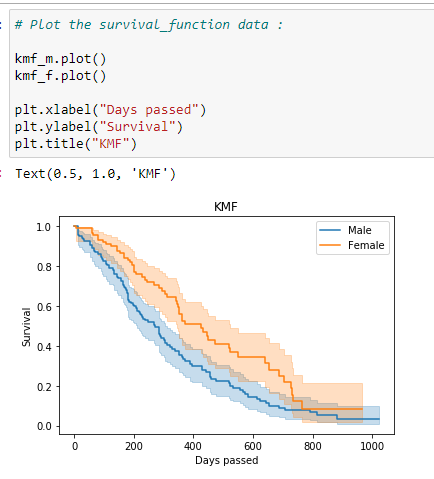
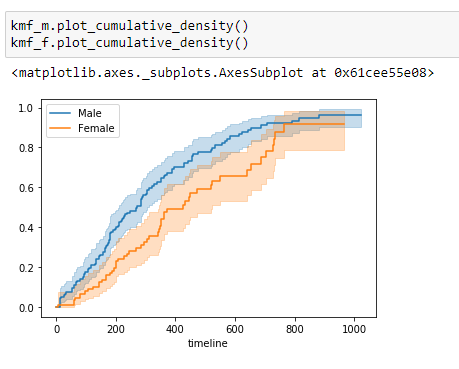
Notez que la probabilité qu’une femme survienne au cancer du poumon est plus élevée que la probabilité qu’un homme survienne au cancer du poumon. Donc, à partir de ces données, nous pouvons dire que les chercheurs médicaux devraient se concentrer davantage sur les facteurs qui conduisent à de faibles taux de survie pour les patients de sexe masculin.
(10) Densité_cumulitive:
Cela nous donne une probabilité qu’une personne meure à un certain moment.
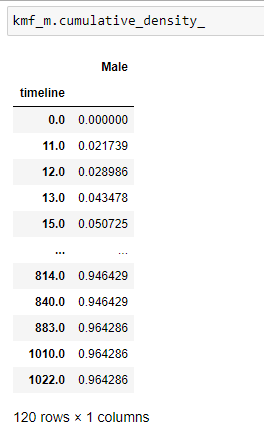
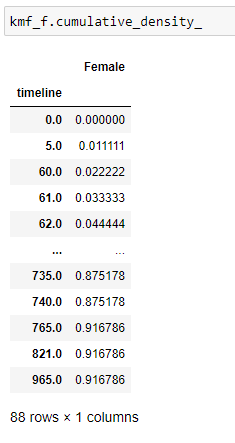
(11) Tracez les données:
(12) Fonction de danger:
(13) Ajustement des données:
(14) Danger cumulatif:
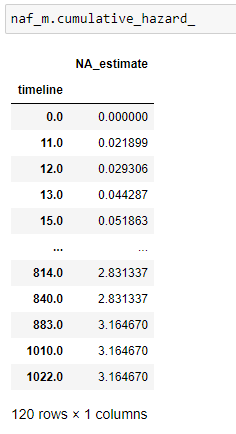
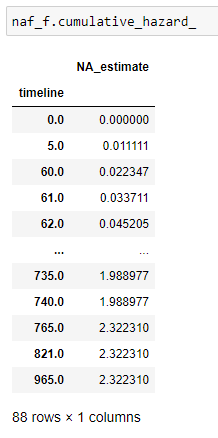
(15) Tracez les données:
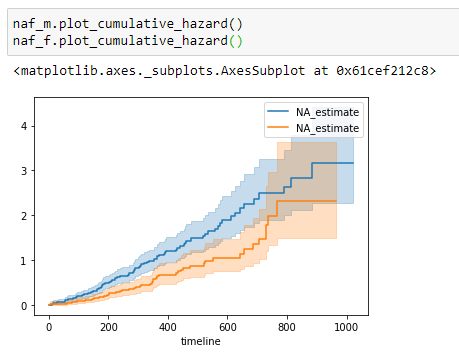
Test du log-rang
Objectif: Ici, notre objectif est de voir s’il existe une différence significative entre les groupes comparés.
Hypothèse nulle: L’hypothèse nulle indique qu’il n’y a pas de différence significative entre les groupes étudiés. S’il y a une différence significative entre ces groupes, nous devons rejeter notre hypothèse nulle.
Comment dire qu’il y a une différence significative?
La signification statistique est désignée par une valeur p comprise entre 0 et 1. Plus la valeur p est petite, plus la différence statistique entre les groupes étudiés est grande. Notez qu’ici notre objectif est de trouver s’il y a une différence entre les groupes que nous comparons. Si oui, nous pouvons faire plus de recherches sur les raisons pour lesquelles les chances de survie sont plus faibles pour un groupe particulier en fonction de diverses informations telles que leur alimentation, leur mode de vie, etc.
Moins de (5% = 0,05) P–valeur signifie qu’il existe une différence significative entre les groupes que nous avons comparés. Nous pouvons partitionner nos groupes en fonction de leur sexe, âge, race, méthode de traitement, etc.
C’est un test pour découvrir la valeur de P.
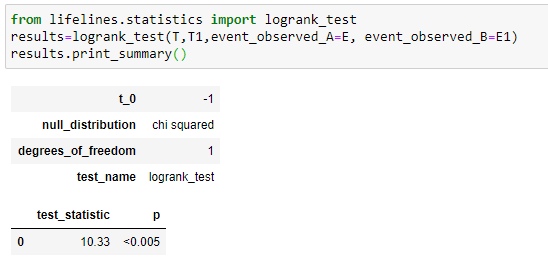
Ici, nous allons comparer les distributions de survie de deux groupes différents par la célèbre méthode statistique du test du log-rank. Notez ici que pour nos groupes, le test_statistic est égal à 10,33 et la valeur P indique (<0,005), ce qui est statistiquement significatif et indique que nous devons rejeter notre hypothèse nulle et admettre que la fonction de survie pour les deux groupes est significativement différente. La valeur P nous donne des preuves solides que le «sexe» était associé aux jours de survie. Bref, on peut dire que dans notre exemple, le «sexe» a une contribution majeure aux jours de survie.
Mettre tous ensemble:
Vous pouvez télécharger les blocs-notes Jupyter à partir d’ici.
Exemple 4: modèle de risque proportionnel de Cox
Le modèle de risque proportionnel de Cox est essentiellement un modèle de régression généralement utilisé par les chercheurs médicaux pour découvrir la relation entre le temps de survie d’un sujet et une ou plusieurs variables prédictives. En bref, nous voulons savoir comment différents paramètres comme l’âge, le sexe, le poids, la taille affectent la durée de survie d’un sujet.
Dans la section précédente, nous avons vu Kaplan-Meier, Nelson-Aalen et Log-Rank Test. Mais en cela, nous n’avons pu considérer qu’une seule variable à la fois. Et une autre chose à noter ici est que nous n’effectuions des opérations que sur des variables catégorielles comme le sexe, le statut, etc., qui ne sont généralement pas utilisées pour des données non catégoriques comme l’âge, le poids, etc. En guise de solution, nous utilisons le Cox analyse de régression des risques proportionnels, qui fonctionne à la fois pour les variables prédictives quantitatives (non catégorielles) et les variables catégorielles.
Pourquoi en avons-nous besoin?
Dans la recherche médicale, en général, nous considérons plus d’un facteur pour diagnostiquer la santé ou la durée de survie d’une personne, c’est-à-dire que nous utilisons généralement son sexe, son âge, sa tension artérielle et sa glycémie pour savoir s’il existe une différence significative entre ceux de différents groupes. Par exemple, si nous regroupons nos données en fonction de l’âge d’une personne, notre objectif sera de déterminer quel groupe d’âge a les meilleures chances de survie. S’agit-il du groupe des enfants, du groupe des adultes ou du groupe des personnes âgées? Maintenant, ce que nous devons trouver, c’est sur quelle base faisons-nous le groupe? Pour trouver que nous utilisons la régression de Cox et trouver les coefficients de différents paramètres. Voyons comment cela fonctionne!
Principes de base de la méthode du risque proportionnel de Cox:
Le but ultime de la méthode du risque proportionnel de Cox est de remarquer comment différents facteurs de notre ensemble de données influent sur l’événement d’intérêt.
Fonction de danger:
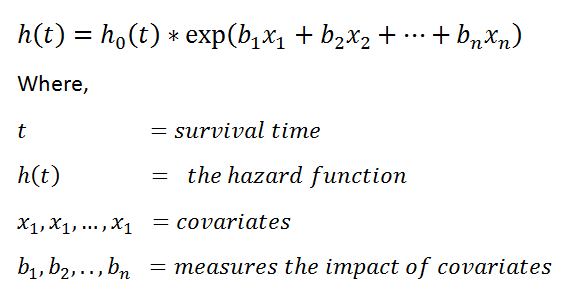
Les valeurs exp (bi) sont appelées le rapport de risque (HR). Le HR supérieur à 1 indique que lorsque la valeur de la ième covariable augmente, le risque d’événement augmente, et donc la durée de survie diminue.
En résumé,

Codons:
(1) Importez les bibliothèques requises:
(2) Lisez le fichier CSV:
(3) Supprimez les lignes contenant des valeurs nulles:
Ici, nous devons supprimer les lignes qui ont des valeurs nulles. Notre modèle ne peut pas fonctionner sur des lignes qui ont des valeurs nulles. Si nous ne prétraitons pas nos données, il se peut que nous obtenions une erreur.
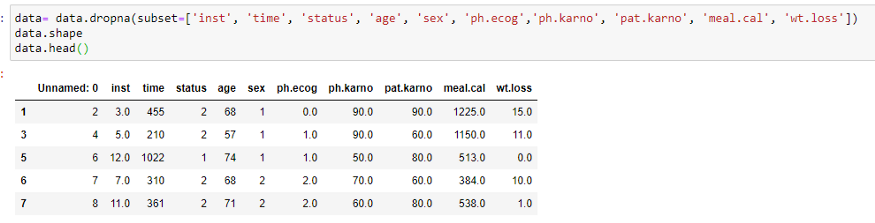
(4) Créez un objet pour KapanMeierFitter:
(5) Organiser nos données:
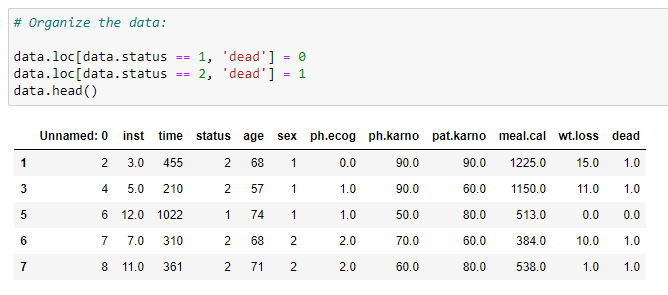
(6) Ajustez les valeurs:
(7) Tableau des événements:
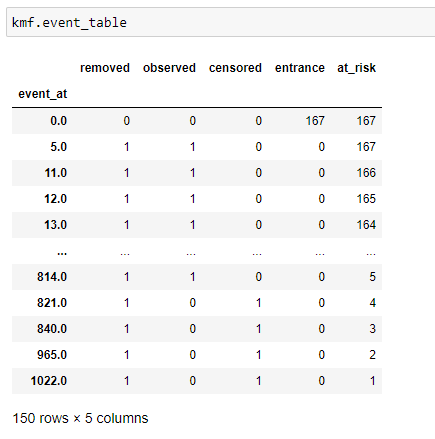
(8) Importer la bibliothèque de régression Cox:

(9) Paramètres que nous voulons prendre en compte lors de l’ajustement de notre modèle:

(10) Ajustez les données et imprimez le résumé:
Notre modèle considérera tous les paramètres pour trouver les valeurs de coefficient pour cela.
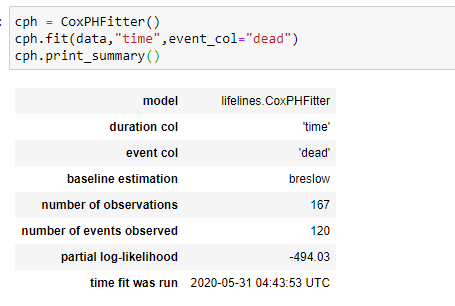
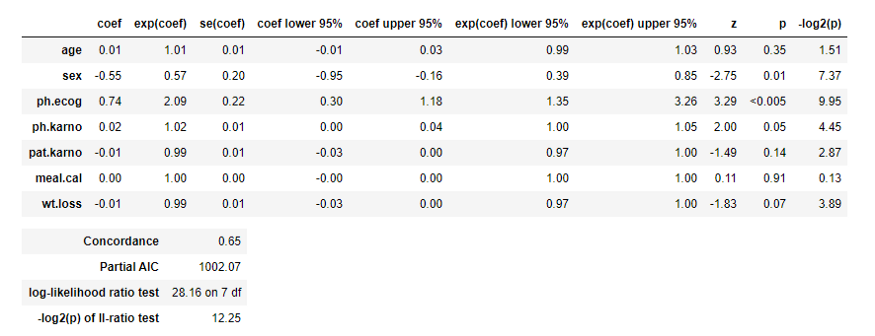
Notez ici la valeur p de différents paramètres car nous savons qu’une valeur p (<0,05) est considérée comme significative. Ici, vous pouvez voir que la valeur p de sex et ph.ecog est <0,05. Ainsi, nous pouvons dire que nous pouvons regrouper nos données en fonction de ces paramètres.
HR (rapport de risque) = exp (bi)
La valeur p pour le sexe est de 0,01 et le HR (Hazard Ratio) est de 0,57, ce qui indique une forte relation entre le sexe des patients et une diminution du risque de décès. Par exemple, en maintenant les autres covariables constantes, être une femme (sexe = 2) réduit le risque d’un facteur 0,58, soit 42%. Cela signifie que les femmes ont des chances de survie plus élevées. Notez que nous sommes arrivés à cette conclusion en utilisant un graphique dans la section précédente.
La valeur p pour ph.ecog est <0,005 et HR est 2,09, indiquant une forte relation entre la valeur ph.ecog et un risque accru de décès. En maintenant les autres covariables constantes, une valeur plus élevée de ph.ecog est associée à une faible survie. Ici, une personne avec une valeur ph.ecog plus élevée a un risque de décès 109% plus élevé. Donc, en bref, nous pouvons dire que les médecins essaient de réduire la valeur de ph.ecog en fournissant des médicaments appropriés.
Notez maintenant que le HR pour l’âge est de 1,01, ce qui suggère une augmentation de seulement 1% pour le groupe d’âge supérieur. On peut donc dire qu’il n’y a pas de différence significative entre les différents groupes d’âge.
En bref,
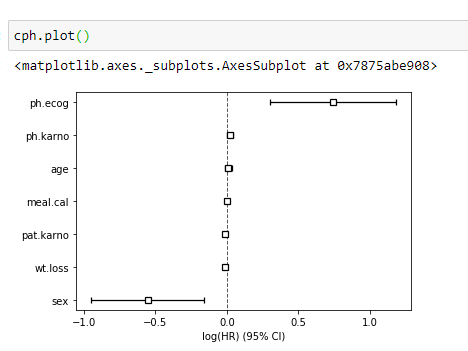
(11) Vérifiez quel facteur affecte le plus à partir du graphique:
Vous pouvez clairement voir que les variables ph.ecog et sexe présentent des différences significatives.
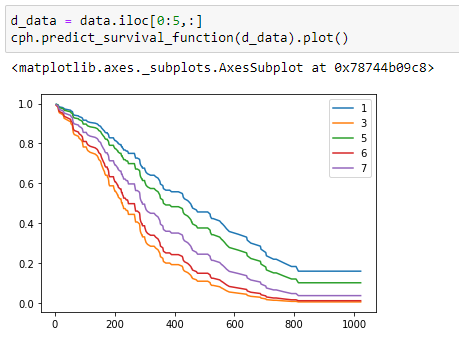
(12) Tracez le graphique:
Ici, j’ai tracé la probabilité de survie pour différentes personnes dans notre ensemble de données. Remarquez ici que la personne 1 a les chances de survie les plus élevées et la personne 3 a les chances de survie les plus faibles. Si vous regardez les données principales, vous pouvez voir que la personne-3 a une valeur ph.ecog plus élevée.
Notez ici que même si la personne 5 est vivante, sa probabilité de survie est moindre car elle a une valeur ph.ecog plus élevée.
(13) Découvrez le temps médian avant l’événement pour la chronologie:
Notez ici qu’au fur et à mesure que le nombre de jours passait, le temps de survie médian diminue.
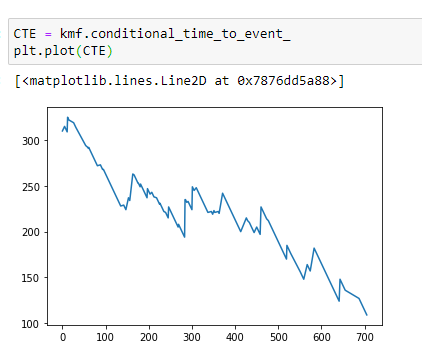
Mettre tous ensemble:
Vous pouvez télécharger les blocs-notes Jupyter à partir d’ici.
Original. Republié avec permission.
Bio: Pratik Shukla est un aspirant ingénieur en apprentissage automatique qui aime présenter des théories complexes de manière simple. Pratik a poursuivi ses études de premier cycle en informatique et poursuit un programme de maîtrise en informatique à l’Université de Californie du Sud. “Viser la lune. Même si vous le manquez, vous atterrirez parmi les étoiles. – Les Brown »
En rapport:
Source de l’article

