Modèles de prédiction de la survie : une introduction à la modélisation en temps discret | BMC Medical Research Methodology

Modèles de survie à temps discret
Les méthodes que nous avons examinées jusqu’à présent ne sont applicables qu’aux temps de survie continus. Dans le cadre du temps discret, nous supposons que les données disponibles sont les mêmes, mais nous définissons différemment la fonction de risque et le lien entre les fonctions de risque et de survie. Nous divisons le temps de survie continu en une séquence de J intervalles de temps contigus (t0,t1],(t1,t2],…,(tJ-1,tJ]où t0=Dans ce cadre, le danger, ou risque instantané de l’événement, dans un intervalle particulier est la probabilité qu’un individu subisse l’événement pendant cet intervalle, étant donné qu’il a survécu jusqu’au début de cet intervalle. Ainsi, en temps discret, le hasard est une probabilité conditionnelle plutôt qu’un taux et, en tant que tel, sa valeur est comprise entre zéro et un. Ainsi, pour un individu avec des covariables de base Xil’aléa dans l’intervalle Aj=(tj-1,tj]peut être exprimée comme la probabilité conditionnelle
$$ \begin{aligned} \lambda_{ij}(X_{i})&=\text{Pr}(T_{i}\in A_{j}|T_{i}>t_{j-1},X_{i})&\;= \text{Pr}(t_{j-1}
et la fonction de probabilité discrète est donnée par
$$f_{ij}=\text{Pr}(T_{i}\in A_{j}|X_{i}) = S(t_{j-1}|X_{i})- S(t_{j}|X_{i}) $$
La probabilité de survivre au-delà d’un certain temps t peut être obtenue comme le produit des probabilités conditionnelles de survie pour tous les intervalles de temps jusqu’à et y compris (tj-1,tj]tel que tj≤t. Ceci est analogue à la spécification de la fonction de survie en temps continu comme étant le risque intégré sur tous les temps précédents. Ainsi, la probabilité de survie en temps discret est donnée par
$$ S_{i}(t|X_{i}) = \text{Pr}(T_{i}>t|X_{i})=\prod_{j:t_{j}\leq t}(1-\lambda_{ij}(X_{i})) $$
(1)
Notez que la relation λij(Xi)=fij/Si(tj-1|Xi) reste valable dans le cadre de ces définitions. Pour construire la vraisemblance, on soumet i contribue au produit des probabilités de survie conditionnelles pour les intervalles de temps au cours desquels ils sont observés mais ne subissent pas l’événement. Les individus qui sont observés comme ayant un échec (c’est-à-dire, δi=1) contribue en outre à la probabilité conditionnelle de défaillance dans l’intervalle \(A_{j_{i}}=(t_{j_{i}-1},t_{j_{i}}]\) au cours de laquelle ils ont vécu l’événement qui nous intéresse. Nous utilisons ji pour désigner le dernier intervalle au cours duquel nous disposons d’informations sur le sujet i, tel que \(\phantom {\dot {i}\!}T_{i}\in A_{j_{i}}\). Sujet i n’apporte aucune information à la vraisemblance pour les intervalles au-delà de \(\phantom {\dot {i}\!}A_{j_{i}}\). Ici, nous ne considérons que la censure à droite, de sorte que la vraisemblance est donnée par
$$\begin{array}{*{20}l} {}L&=\!\prod_{i=1}^{n} \left[\text{Pr}(T_{i}=t_{j_{i}})\right]^{\delta_{i}}\N- gauche[\text{Pr}(T_{i}>t_{j_{i}})\right]^{1-\delta_{i}}\\ {}&=\!\prod_{i=1}^{n}\left[\!\lambda_{ij_{i}}(X_{i})\prod_{j=1}^{j_{i}-1}(1-\lambda_{ij}(X_{i}))\!\right]^{\delta_{i}}\N-\Nà gauche[\prod_{j=1}^{j_{i}}(1-\lambda_{ij}(X_{i}))\right]^{1-\delta_{i}} \N-end{array} $$
où \(t_{j_{i}}\) indique que le sujet i a une durée de survie dans l’intervalle \(\phantom {\dot {i}\!}(t_{j_{i}-1}, t_{j_{i}}])
\). Nous pouvons introduire un indicateur d’historique des événements \(\phantom {\dot {i}\!}d_{ij}=I(T_{i}\in A_{j_{i}})=I(t_{j-1}
$$ L=\prod_{i=1}^{n}\prod_{j=1}^{j_{i}}\lambda_{ij}(X_{i})^{d_{ij}}(1-\lambda_{ij}(X_{i}))^{1-d_{ij}} $$
(2)
qui est équivalent à la vraisemblance d’un modèle binomial avec des observations indépendantes dij, des probabilités spécifiques au sujet λij(Xi) pour le sujet i vivre l’événement dans l’intervalle (tj-1,tj]et des covariables fixées dans le temps Xi. Il convient de noter que nous ne faisons pas l’hypothèse que les indicateurs d’événements au sein d’un sujet sont indépendants et ont une distribution binomiale. Au lieu de cela, nous observons que la fonction de vraisemblance pour le modèle de survie à temps discret sous censure non informative peut être représentée à l’aide d’une vraisemblance binomiale qui suppose des indicateurs d’événements indépendants [27].
Pour construire cette vraisemblance à partir de nos données, nous devons les convertir en un ensemble de données personne-période, comme le montre la figure 1. Les sujets fournissent une ligne pour chaque intervalle de temps pendant lequel ils sont encore à risque au début, c’est-à-dire que tous les j tel que T> ;tj-1. Chaque enregistrement contient l’indicateur d’échec du sujet pour avoir vécu l’événement pendant cet intervalle (c’est-à-dire l’indicateur de l’historique de l’événement). dij), une copie de leur vecteur de covariables de référence Xiet une variable factorielle identifiant l’intervalle Aj auquel l’enregistrement correspond.
Exemple d’un ensemble de données personne-période (à droite) créé à partir de données de survie en temps continu (à gauche). Dans le diagramme chronologique, les cercles indiquent la censure et les losanges indiquent les événements. L’horizon d’intérêt est w=5 et il y a J=5 intervalles spécifiés définis comme 1 : A1=(t0,t1], 2 : A2=(t1,t2], 3 : A3=(t2,t3], 4 : A4=(t3,t4], 5 : A5=(t4,t5]dont les extrémités sont données par t0=0, t1=1, t2=2, t3=3, t4=4, t5=5. L’ID 1 subit un événement dans l’intervalle 3 et, par conséquent, dans l’ensemble de données sur les périodes-personnes, il a des lignes correspondant aux trois premiers intervalles et, pour le troisième intervalle, son statut d’événement est 1. L’ID 2 est censuré dans l’intervalle 4 et, dans l’ensemble de données sur les périodes-personnes, il a des lignes correspondant aux quatre premiers intervalles et son statut d’événement est 0 pour chacun d’entre eux. L’ID 3 subit l’événement à un moment qui dépasse l’horizon de prédiction qui nous intéresse, nous le censurons donc administrativement à l’horizon de prédiction et il a une ligne dans la période-personne pour tous les intervalles et a un statut d’événement de 0 pour tous les intervalles.
En raison de la structure binomiale de la fonction de vraisemblance dans l’équation (2), la formulation du temps de survie discret est générale et tout algorithme capable d’optimiser une log-vraisemblance binomiale peut être utilisé pour obtenir des estimations de paramètres. Ainsi, dans le cadre de cette approche, nous pouvons appliquer n’importe quelle méthode de calcul de la probabilité d’un événement binaire et choisir parmi diverses méthodes de classification binaire, depuis les méthodes de régression traditionnelles jusqu’aux approches d’apprentissage automatique plus complexes. L’estimation peut être effectuée en appliquant ces méthodes à l’ensemble de données personne-période décrit. Les estimations qui en résultent peuvent ensuite être utilisées dans l’équation (1) pour calculer la probabilité de survie prédite pour une période de suivi donnée.
L’avantage d’une approche de survie à temps discret est qu’elle ne nécessite pas d’hypothèse de risques proportionnels pour la distribution du temps de survie. En outre, elle offre une interprétation plus intuitive puisque la fonction de risque représente la probabilité de subir l’événement dans un intervalle si la personne est en vie au début de l’intervalle. Les modèles à temps discret sont également capables de traiter des temps de défaillance liés sans ajustement [26]comme l’exige la modélisation du PH de Cox en raison de son hypothèse d’un risque continu dans lequel les égalités ne sont pas possibles. [3].
Modèles de classification paramétrique
Cox (1972) a proposé qu’étant donné qu’en temps discret les aléas, λijsont des probabilités, elles peuvent être paramétrées pour avoir une dépendance logistique avec les prédicteurs et les intervalles de temps [4, 27]. En d’autres termes, nous supposons que les prédicteurs sont linéairement associés à la transformation logistique du danger (logit-danger) plutôt qu’aux probabilités de danger elles-mêmes. Plus précisément, les probabilités conditionnelles de subir une défaillance dans chaque intervalle de temps (tj-1,tj](étant donné qu’il ne s’est pas encore produit) est supposé être une fonction linéaire des effets du prédicteur et de l’intervalle. Ce modèle est appelé modèle du ratio de continuationet est spécifié comme suit
$$ \log\left(\frac{\lambda_{ij}}{1-\lambda_{ij}}|X_{i}\right) = \alpha_{j} + \beta X_{i} $$
(3)
où αj est le logit du risque de base pour l’intervalle (tj-1,tj]et β décrit l’effet des autres covariables sur le risque de base sur l’échelle logit, comme dans une régression logistique. En d’autres termes, pour un prédicteur binaire Xipune estimation positive (négative) du coefficient de βp indique un déplacement vers le haut (vers le bas) du logit-hazard pour les personnes ayant un revenu de Xip=1 de l’aléa logit pour ceux qui ont une Xip=Ainsi, en prenant l’exponentielle des deux côtés de l’équation (3), nous constatons que les chances sont proportionnelles pour ceux qui ont Xip=Cette propriété empêche les risques discrets des deux groupes de se croiser. Cela exclut le scénario dans lequel les prédicteurs ont des effets protecteurs à court terme sur la survie mais sont inférieurs à des moments ultérieurs. Notez également que cet effet n’est pas une fonction du temps et qu’il est donc supposé être constant pour toutes les périodes.
Dans la vraisemblance donnée par l’équation (2), le modèle du ratio de continuation suppose que le modèle de classification pour la survie à long terme est le même que le modèle de classification pour la survie à long terme. λij(Xi) est une régression logistique. L’estimation est réalisée en obtenant des estimations du maximum de vraisemblance de αj et β à l’aide d’un logiciel de régression logistique standard appliqué à l’ensemble de données personne-période. Avec les estimations de αj et βon peut alors calculer λkj(Xk) pour un nouveau sujet k de la même population pour tous les intervalles de temps jet calcule ensuite la prédiction de survie donnée dans l’équation (1).
Avec le modèle logistique, lorsque l’ampleur des risques est faible, nous constatons que les chances d’échec se rapprochent de la probabilité d’échec (c’est-à-dire, λij/(1-λij)≈λij) et que les risques du modèle des chances proportionnelles et du modèle des risques proportionnels se rapprochent l’un de l’autre. Le modèle du rapport de continuation converge vers le modèle de Cox lorsque la longueur des intervalles à temps discret devient nulle (c’est-à-dire lorsque le nombre d’intervalles de temps dans une période fixe augmente). [45].
Dans le paramétrage g(λij|Xi)=αj+βXinous pouvons aussi considérer des modèles avec d’autres fonctions de liaison pour les g qui sont couramment utilisés pour les résultats binaires. Le modèle de Gompertz ou le modèle des risques proportionnels groupés qui utilise un lien log-log complémentaire, log(- log(λij|Xi)), est un équivalent en temps discret du modèle PH de Cox. D’autres paramétrages incluent le modèle probit (lien probit), Φ-1(λij|Xi), le modèle de Gumbel (lien log-log), – log(- log(λij|Xi)), ou le modèle exponentiel (log link), log(λij|Xi). À des fins de prédiction, le choix du lien peut être basé sur la performance prédictive des différents modèles. Il a été démontré que les différences entre les différents modèles sont faibles si la longueur des intervalles à temps discret est très courte [45].
Les modèles de risques proportionnels en temps continu et les modèles paramétriques en temps discret reposent sur une hypothèse de proportionnalité, qui peut être restrictive. En outre, ces modèles supposent que l’effet des prédicteurs sur le risque transformé est linéaire. Une extension permettant de prendre en compte les effets non linéaires consiste à utiliser une régression semi-paramétrique dans laquelle le risque de base et les effets des covariables sont spécifiés comme des fonctions lisses, éventuellement non linéaires, du temps, c’est-à-dire.., \(\lambda _{ij}=f_{0}(j)+\sum _{p=1}^{P}f_{p}(X_{ip})\)et f0 et fp peuvent être choisies comme des fonctions splines [46]. Cette méthode peut également être étendue pour prendre en compte les risques non proportionnels et les effets de covariables variables dans le temps en spécifiant fp en fonction du temps, comme par exemple fp(Xip,t)=fp(Xip)-t. Bien que ces extensions puissent accroître la flexibilité des approches de modélisation paramétrique, elles peuvent toujours ne pas capturer de manière adéquate les relations qui existent dans les données. Ces relations doivent être connues et spécifiées dans le processus de construction du modèle. Il peut donc être intéressant d’explorer des approches flexibles et non paramétriques pour décrire la dépendance entre le hasard et les prédicteurs dans le cadre de la survie à temps discret.
Modèles de classification par apprentissage automatique
Une autre approche pour spécifier cette dépendance consiste à utiliser une approche d’apprentissage automatique non paramétrique, telle que les forêts aléatoires et les réseaux neuronaux, sous la forme suivante
$$ \lambda_{ij}(X_{i})=f(X_{i}, A_{j}) $$
où f est un algorithme ou un modèle particulier d’apprentissage automatique, Xi est la covariable spécifique au sujet, et Aj est la variable catégorielle indiquant l’intervalle de temps.
Nous adaptons un algorithme d’apprentissage automatique, fà l’ensemble de données personne-période pour le résultat binaire de l’échec, le vecteur de prédicteurs étant les covariables spécifiques au patient et la variable catégorielle identifiant l’intervalle de temps discret. Pour un nouveau patient k avec covariables Xknous pouvons alors obtenir des estimations sans modèle des probabilités conditionnelles \(\hat {\lambda }_{kj}(X_{k})\) pour chaque intervalle j=0,…,J. Ces estimations peuvent ensuite être introduites dans l’équation (1), pour obtenir la prédiction de survie pour le patient k jusqu’à l’heure t, c’est-à-dire, πk(t).
Le développement de modèles de prédiction utilisant un cadre à temps discret a été démontré avec des méthodes semi-paramétriques [46]des méthodes basées sur des arbres [29, 30]et les réseaux neuronaux [31, 33, 47]. Avec une approche de survie à temps discret, nous pouvons tirer parti des logiciels disponibles et de l’efficacité de calcul des algorithmes de classification binaire pour prédire les probabilités de survie qui nous intéressent. Dans cette classe de modèles de prédiction plus flexibles, nous pouvons également envisager des approches de régression pénalisées telles que lasso, ridge et elastic net. [48]. Ces approches et leurs implémentations logicielles correspondantes peuvent s’adapter à des méthodes de classification binaire supplémentaires sans nécessiter d’estimation ou d’optimisation spécifique à la méthode pour obtenir les probabilités de survie prédites.
Réglage des hyperparamètres
Avec les algorithmes d’apprentissage automatique, il est généralement nécessaire de spécifier un hyperparamètre. hyperparamètre. Il s’agit de paramètres qui ne peuvent pas être estimés mais qui sont spécifiés pour contrôler le processus d’apprentissage du modèle. Par exemple, dans la forêt aléatoire, il existe des hyperparamètres correspondant au nombre d’arbres de décision dans la forêt et au nombre de prédicteurs pris en compte à chaque division. Des valeurs élevées pour chacun de ces hyperparamètres peuvent augmenter le temps de calcul nécessaire à l’apprentissage de la forêt aléatoire. Dans le LASSO, l’hyperparamètre est un paramètre de régularisation qui est ajouté à la régression par les moindres carrés ordinaires, de sorte que des valeurs plus élevées pénalisent l’algorithme pour l’inclusion d’un trop grand nombre de coefficients non nuls, ce qui permet d’effectuer une sélection des variables.
Les valeurs optimales de l’hyperparamètre ne sont pas déterminées théoriquement ou basées sur des connaissances préalables, mais peuvent être accordées à l’aide de résultats empiriques. En d’autres termes, pour une grille de valeurs d’hyperparamètres possibles ou de combinaisons de valeurs lorsqu’il y a plusieurs hyperparamètres, nous pouvons évaluer les performances d’un algorithme pour chaque ensemble de valeurs et sélectionner les valeurs qui conduisent à la meilleure performance prédictive. Pour éviter le surajustement, nous pouvons procéder à l’ajustement des hyperparamètres à l’aide de la validation croisée. Nous sélectionnons ensuite les valeurs des hyperparamètres qui optimisent les performances de la mesure de performance validée par validation croisée. Ces valeurs d’hyperparamètres sont ensuite utilisées pour entraîner l’algorithme sur l’ensemble des données d’entraînement afin de construire le modèle de prédiction.
Avec l’utilisation de modèles de classification binaire dans le cadre de la survie en temps discret, outre les hyperparamètres requis par la méthode de classification binaire employée, nous pouvons également régler le nombre d’intervalles de temps utilisés pour la discrétisation. Il a été démontré que la précision des performances des modèles à temps discret varie en fonction du nombre d’intervalles utilisés [49]. Ainsi, au lieu de spécifier le nombre d’intervalles, nous pouvons également considérer qu’il s’agit d’un hyperparamètre pour lequel une grille appropriée de valeurs possibles est explorée afin d’équilibrer la complexité de calcul et la maximisation de la performance prédictive.
Le choix de la mesure de performance utilisée pour la mise au point doit être le même que celui de la mesure utilisée pour l’évaluation de la performance globale. Dans le cas contraire, les modèles optimisés pourraient ne pas présenter de performances supérieures à celles d’autres modèles construits à l’aide du même algorithme, et donc ne pas permettre une comparaison équitable lors de l’identification de la meilleure méthode parmi plusieurs classes de modèles et d’algorithmes de prédiction. Nous décrivons les mesures de performance pour les modèles de survie dans une section ultérieure.
Autres approches
Dans une approche alternative de l’estimation, certains recommandent une manière différente de spécifier la contribution des sujets censurés. Si le temps de survie de l’individu censuré se situe dans la seconde moitié de l’intervalle Aj-1 ou la première moitié de l’intervalle Aj, c’est-à-dire, \(\frac {1}{2}(t_{j-2}+t_{j-1})\leq T_{i} < ; \frac {1}{2}(t_{j-1}+t_{j})\)nous pouvons considérer leur contribution à la vraisemblance comme le produit des probabilités de survie conditionnelles de j=1,…,j-1 [16, 32]. Ainsi, un sujet n’est compté pour avoir survécu à un intervalle que s’il a survécu à au moins la moitié de cet intervalle. Cela contraste avec notre spécification actuelle qui inclut tous les intervalles pendant lesquels le sujet censuré a observé des informations. Dans le cas où il y a beaucoup de censure dans les données ou qu’il y a moins d’intervalles spécifiés avec des longueurs plus importantes, notre spécification actuelle peut biaiser le hasard estimé vers le bas et la survie prédite vers un, ce qui fait de cette méthode alternative une stratégie utile à poursuivre. Une autre spécification consisterait à considérer les observations censurées dans l’intervalle Aj comme étant censuré à la fin de l’intervalle Aj-1. Cela imite la collecte de données à temps discret typique, où si un individu est perdu pour le suivi entre les temps de mesure tj-1 et tjnous les aurions observés pour la dernière fois à tj-1. La figure 2 montre comment l’ensemble de données personne-période serait créé selon chacune de ces spécifications.
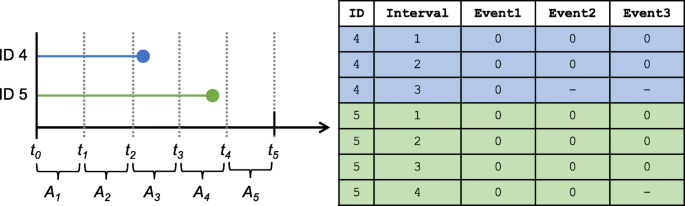
Démonstration de différentes spécifications de censure pour créer un ensemble de données personne-période (à droite) à partir de données de survie en temps continu de deux individus censurés (à gauche). L’horizon d’intérêt est w=5 et il y a J=5 intervalles définis comme suit Aj=(tj-1,tj]pour j∈{1,2,3,4,5}. Trois spécifications différentes sont données pour savoir si un individu contribue à un intervalle particulier (événement 1 : intervalles pendant lesquels l’individu est observé, événement 2 : intervalles pour lesquels il survit au moins à la moitié de l’intervalle, événement 3 : intervalles pour lesquels il survit à l’ensemble de l’intervalle). L’ID 4 est censuré dans la première moitié de l’intervalle 3, de sorte que dans l’ensemble de données personne-période, il ne contribue pas à l’intervalle 3 dans la spécification Event2 et Event3. L’ID 5 est censuré dans la seconde moitié de l’intervalle 4, de sorte que dans l’ensemble de données personnes-périodes pour l’intervalle 4, il contribue selon la spécification Event2 mais pas selon la spécification Event3 puisqu’il ne survit pas jusqu’à la fin de l’intervalle.
Il existe également d’autres approches de prédiction dans le cadre du temps discret. Dans l’équation (1), nous démontrons que la fonction de survie peut être écrite comme une séquence de prédictions provenant de modèles de classification binaire. Jusqu’à présent, l’approche de classification binaire que nous avons examinée modélise directement les probabilités conditionnelles (ou aléas) et utilise les estimations qui en résultent pour calculer la probabilité de survie. En raison de la dépendance des résultats de ces modèles de classification (c’est-à-dire qu’un décès dans un intervalle particulier implique un décès dans tous les intervalles suivants), nous pouvons envisager de modéliser la distribution de survie directement comme une série de modèles de classification dépendants. Cela peut être considéré comme un problème d’apprentissage multitâche, où les modèles de classification associés sont résolus en parallèle [50].
Yu et al. (2011) [51] ont proposé d’utiliser la régression logistique multitâche qui spécifie un modèle de régression logistique pour la probabilité de survie conditionnelle de chaque intervalle de temps discret et modélise directement la fonction de survie en combinant ces modèles de classification locaux. Cette approche estime les paramètres du modèle à travers ces modèles de régression logistique conjointement en utilisant un algorithme d’optimisation qui utilise deux régularisateurs, une régularisation de la norme euclidienne des paramètres pour empêcher l’ajustement excessif, et un second régularisateur qui garantit que les paramètres varient en douceur au cours des intervalles de temps consécutifs. Li et al. (2016) [52] propose également une approche d’apprentissage multitâche avec la régression logistique qui utilise un ℓ2,1-Le modèle de Cox PH est basé sur une pénalité de normalité afin d’obtenir une représentation partagée entre les problèmes de classification dépendants, ce qui encourage l’éparpillement et limite l’ajustement excessif, et réduit ainsi l’erreur de prédiction de chaque tâche. Ces méthodes se sont avérées plus performantes que le modèle PH de Cox [49, 51]. D’autres approches ont utilisé un cadre multitâche pour la prédiction de la survie en temps discret en appliquant une approche d’apprentissage profond à la série de tâches de classification binaire [47]et ont été étendues pour prendre en compte les risques concurrents [53].
Bender et al (2020) [54] décrit en utilisant un cadre de régression de Poisson appliqué à des données de survie continues qui spécifie le risque comme un modèle de PH exponentiel par morceaux et utilise une log-vraisemblance de Poisson pour l’estimation. On peut alors appliquer la gamme d’algorithmes d’apprentissage automatique qui peuvent optimiser une log-vraisemblance de Poisson (au lieu d’une log-vraisemblance binomiale) pour effectuer l’estimation, ce qui, de manière similaire à l’approche de classification décrite, permet d’appliquer une variété d’algorithmes existants à la prédiction de la survie. Lorsque l’on observe un temps continu et que l’on souhaite le considérer dans un cadre de temps discret, cette approche peut être préférable en raison de sa robustesse par rapport au choix des intervalles. En outre, nous pouvons utiliser des informations sur l’observation partielle d’un sujet dans un intervalle au lieu de supposer qu’un sujet censuré survit à la totalité du dernier intervalle dans lequel il a été observé.
Construire des modèles de prédiction de survie à temps discret
La figure 3 présente une visualisation de la procédure de construction et de test d’un modèle de prédiction de survie, qui comprend les éléments suivants.
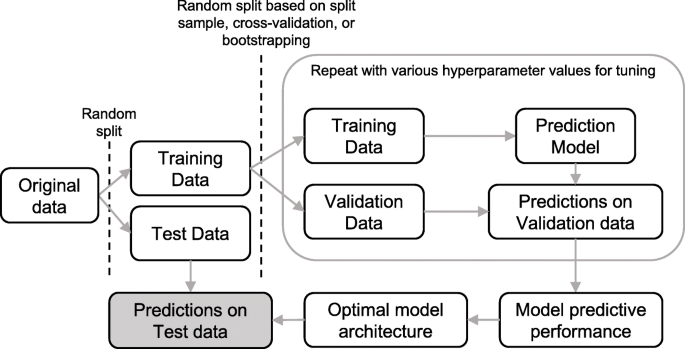
Visualisation du processus de construction et de test du modèle
Préparation des données
L’ensemble des données doit consister en des enregistrements au niveau individuel, de sorte qu’il y ait une seule ligne pour chaque individu avec une colonne distincte pour chaque prédicteur de base. Il doit également contenir une colonne pour le temps de suivi du sujet et une colonne indiquant le statut de l’événement à ce moment-là. Si des sujets manquent ces deux variables, ils doivent être exclus de l’ensemble des données. Si d’autres covariables manquent, elles peuvent être supprimées de l’ensemble des données afin d’effectuer une analyse complète des cas. D’autres méthodes d’imputation, telles que l’utilisation de forêts aléatoires [55, 56]peuvent être appliquées à un ensemble de données de covariables excluant les colonnes de temps de suivi et d’indicateurs d’événements afin de compléter les valeurs manquantes des prédicteurs.
Entraînement au modèle
Pour entraîner notre modèle, nous définissons un ensemble de données d’entraînement approprié en fonction de notre procédure de validation. Si nous utilisons une répartition 60/20/20 formation/validation/test, nous sélectionnons au hasard 60 % de notre ensemble de données complet comme données de formation, 20 % comme ensemble de données de validation utilisé pour évaluer le modèle et sélectionner les hyperparamètres, et les 20 % restants comme ensemble de données d’attente utilisé pour l’évaluation finale du modèle. Si nous utilisons une approche de validation croisée ou de bootstrapping, nous intégrons le reste des composants suivants dans une boucle qui divise aléatoirement les données en plis (validation croisée) ou en rééchantillons avec remplacement (bootstrapping), en identifiant l’ensemble de données d’entraînement et de test approprié pour chaque itération de la boucle.
Pour les modèles de survie à temps discret, nous créons l’ensemble de données personne-période pour entraîner les modèles à l’aide des données d’entraînement. Nous discrétisons les temps de survie continus en intervalles. Les intervalles correspondent à des points dans le temps au cours du suivi où le hasard estimé (probabilité de risque conditionnelle) est autorisé à changer. Ces intervalles peuvent être choisis en fonction du contexte clinique (c’est-à-dire les moments où le risque conditionnel est censé changer). Par exemple, dans un contexte clinique où les patients présentent un risque élevé au cours d’une période de suivi particulière et bénéficient d’un traitement et d’une surveillance supplémentaire, on pourrait augmenter le nombre d’intervalles au cours de cette période afin de refléter l’évolution fréquente du risque conditionnel. L’horizon peut être choisi comme le maximum des temps de prédiction d’intérêt, ou un temps de suivi cliniquement pertinent. La censure administrative est alors appliquée à cet horizon temporel, de sorte que les individus qui subissent un événement ou sont censurés après l’horizon ont une durée de survie qui correspond à l’horizon temporel et sont supposés ne pas avoir subi d’événement à ce moment-là. Cela limite la taille de l’ensemble de données personne-période qui en résulte et réduit la complexité des calculs. L’intervalle de temps résultant, de la ligne de base à l’horizon, est ensuite divisé en un nombre spécifié d’intervalles. Les intervalles de temps peuvent être uniformément espacés sur la plage des temps d’événement dans l’horizon, mais ils ne doivent pas nécessairement être de longueur égale et peuvent être identifiés sur la base des quantiles des temps d’événement. Dans ce manuscrit, nous considérons une approche générale qui nécessite de spécifier le nombre d’intervalles et d’identifier ensuite les intervalles spécifiques sur la base des quantiles des temps d’événements dans un horizon temporel particulier.
Réglage des hyperparamètres
Certaines méthodes d’apprentissage automatique nécessitent la spécification d’hyperparamètres qui doivent être réglés pour optimiser les performances. Dans le tableau A1 du fichier supplémentaire, nous décrivons les hyperparamètres pour les méthodes considérées dans ce manuscrit. Pour les modèles de prédiction à temps discret, nous traitons en outre le nombre d’intervalles comme un hyperparamètre [49]. Le réglage peut être effectué en identifiant une plage raisonnable pour les valeurs de l’hyperparamètre, en sélectionnant une méthode d’échantillonnage des valeurs et en sélectionnant une métrique pour évaluer la performance. Le modèle est ajusté pour toutes les valeurs d’hyperparamètres échantillonnées et évalué sur les données de validation. Les valeurs d’hyperparamètre ajustées sont sélectionnées comme étant celles qui optimisent la mesure de performance. Les méthodes d’échantillonnage des valeurs comprennent la recherche en grille, la recherche aléatoire et l’optimisation bayésienne qui utilise les résultats de l’itération précédente pour améliorer l’échantillonnage des valeurs d’hyperparamètre pour l’itération en cours [57–59]. La mesure de performance peut être évaluée à l’aide d’un ensemble de données de validation indépendantes, de la validation croisée ou du bootstrapping.
Test de modèle
Nous appliquons les modèles formés à l’ensemble de données de test pour obtenir les probabilités de survie prédites pour les horizons de prédiction spécifiés qui nous intéressent. Pour les modèles à temps discret, nous devons créer un ensemble de données personne-période pour les données de test. Nous calculons des mesures de performance pour comparer ces prédictions aux résultats observés dans l’ensemble de données. Cette étape permet d’évaluer la généralisation du modèle formé à un nouvel ensemble de données et d’identifier des problèmes tels que le surajustement. Dans le cas d’une approche de validation croisée ou de bootstrapping, les mesures de performance du test du modèle sont moyennées sur plusieurs itérations. Les résultats de cette étape sont comparés pour les différents modèles afin d’identifier le modèle optimal ou l’architecture du modèle à partir duquel obtenir des prédictions à partir d’un nouvel individu de la même population.
Source de l’article

