Statistiques

Origin offre un certain nombre d’options pour effectuer une analyse statistique générale, notamment: des statistiques descriptives, des tests d’hypothèse à un ou deux échantillons et une analyse de variance unidirectionnelle et bidirectionnelle (ANOVA). En outre, plusieurs types de graphiques statistiques sont pris en charge, y compris les histogrammes et les graphiques en boîte
Des outils d’analyse statistique avancés, tels que l’ANOVA à mesures répétées, l’analyse multivariée, les courbes des caractéristiques de fonctionnement du récepteur (ROC), les calculs de puissance et de taille d’échantillon, et les tests non paramétriques sont disponibles dans OriginPro.
Statistiques descriptives
Origin fournit les outils suivants pour vous aider à résumer vos données continues et discrètes.
Descriptif
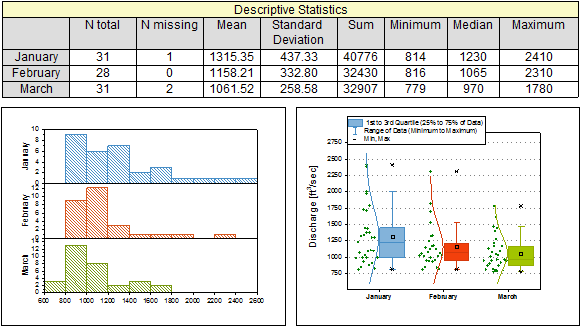
L’opération Statistiques sur les colonnes / lignes effectue des statistiques descriptives par colonne / par ligne sur les données de feuille de calcul sélectionnées.
Statistiques sur les colonnes
Effectue des statistiques descriptives par colonne sur des données groupées ou brutes.
Statistiques sur les lignes
Effectue des statistiques descriptives par ligne pour générer des statistiques pour les lignes de la feuille de calcul.
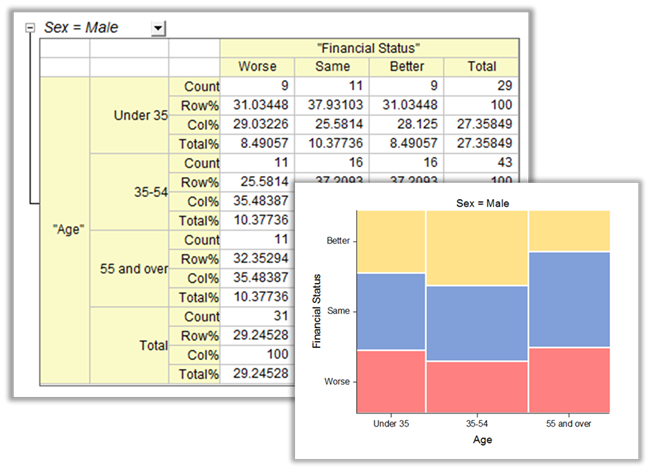
La tabulation croisée (également connue sous le nom de tableau de contingence) est un tableau pour révéler la distribution de fréquence des variables. L’analyse basée sur le tableau peut déterminer s’il existe une relation significative, obtenir la force et la direction de la relation, et mesurer et tester la concordance des données de paires appariées. Il est largement utilisé pour analyser des données catégorielles.
Les fréquences
Fréquence discrète
L’analyse de fréquence discrète est une méthode courante pour analyser des variables discrètes. Il compte la fréquence des données discrètes, y compris le pourcentage et le pourcentage cumulé.
Comptes de fréquence
La fonction calcule les comptages de fréquence pour les données 1D et aide à produire l’histogramme de la manière souhaitée.
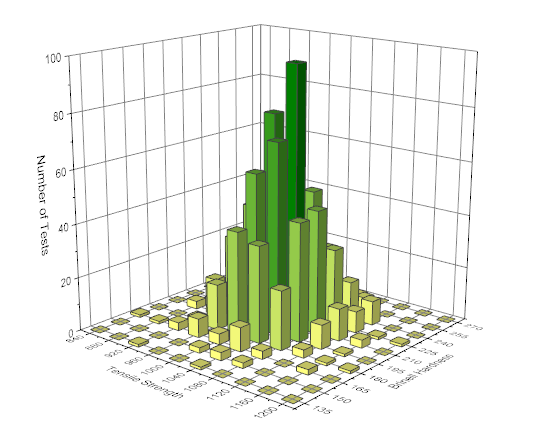
Comptage de fréquence 2D / Binning
Un outil utile pour calculer les nombres de fréquences et tracer l’histogramme 2D pour les données 2D / bivariées.


Test de normalité
Un test de normalité est utilisé pour déterminer si les données d’échantillon ont été tirées d’une population normalement distribuée (dans une certaine tolérance).
Six tests de normalité différents sont disponibles dans Origin:
- Shapiro-Wilk
- Kolmogorov-Smirnov
- Lilliefors
- Anderson-Darling
- K-Squared D’Agostino
- Chen-Shapiro
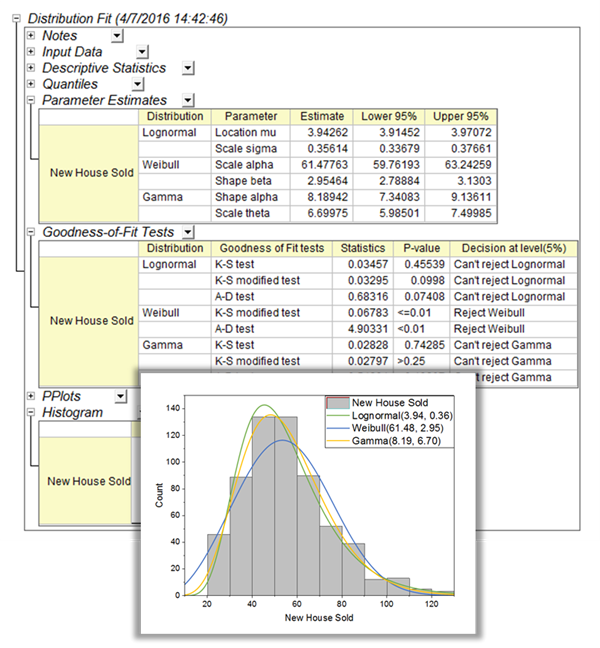
Distribution Fit PRO
Connaître le modèle de distribution des données vous aide à poursuivre la bonne analyse. ou faites une estimation de vos données. le Distribution Fit L’outil aide les utilisateurs à examiner la distribution de leurs données et à estimer les paramètres de la distribution
Coefficient de corrélation PRO
Coefficient de corrélation PRO
Le coefficient de corrélation, également appelé coefficient de corrélation croisée, est une mesure de la force de la relation entre les paires de variables. Origin fournit des mesures de corrélation à la fois paramétriques et non paramétriques.
- Corrélation r de Pearson
- Corrélation de l’ordre de rang de Spearman
- Corrélation Tau de Kendall
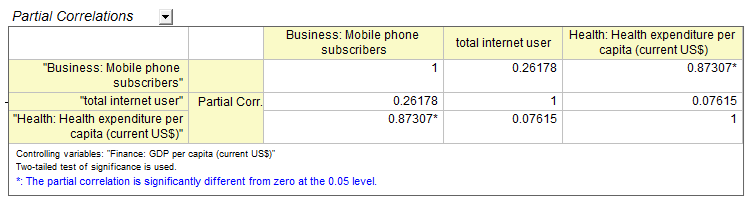
Coefficient de corrélation partielle PRO
La corrélation partielle mesure la relation linéaire entre deux variables aléatoires, après avoir exclu les effets d’une ou plusieurs variables de contrôle.


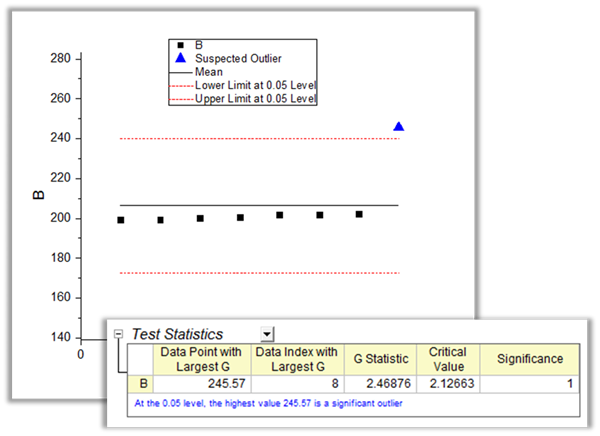
Détection des valeurs aberrantes
Une valeur aberrante est une observation qui est considérablement éloignée du reste des données. Origin fournit deux outils pour aider à détecter les valeurs aberrantes.
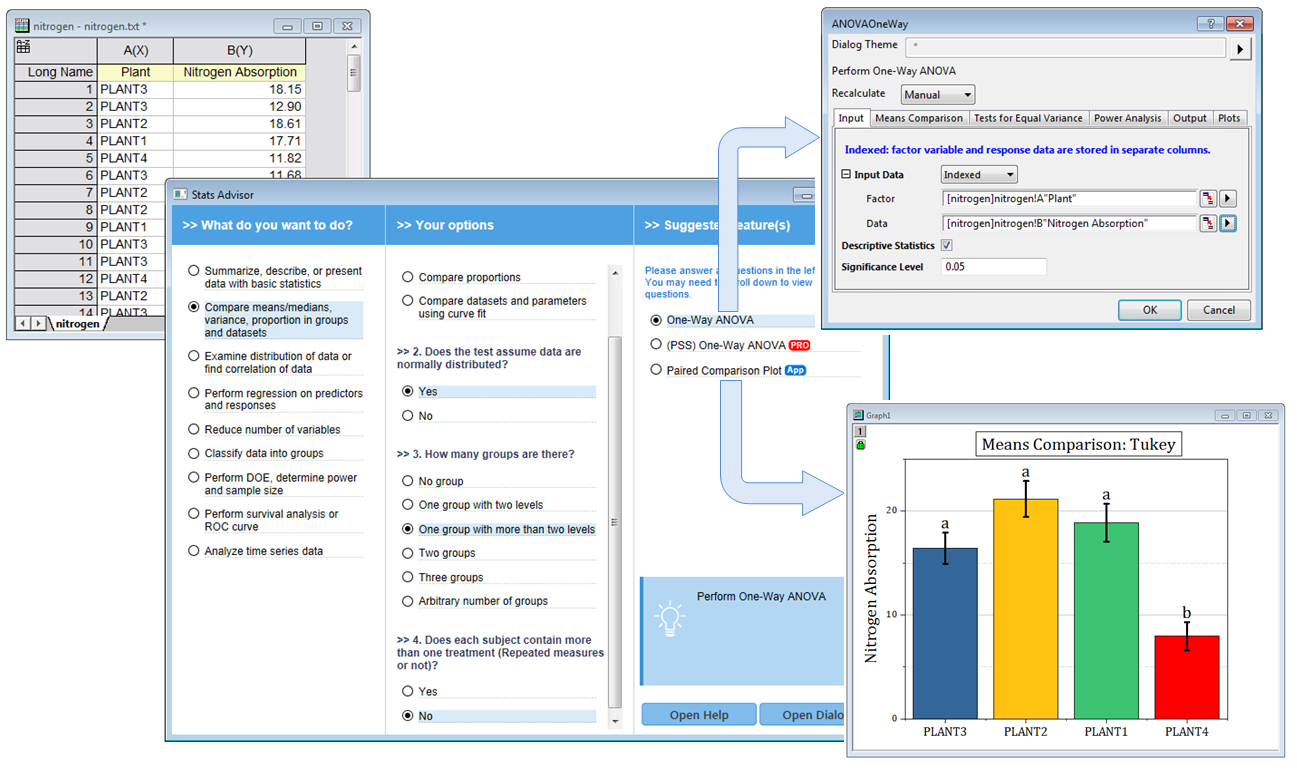
ANOVA
L’analyse de variance (ANOVA) est utilisée pour examiner les différences entre les moyennes des groupes. En plus de déterminer qu’il existe des différences entre les moyens, les outils ANOVA d’Origin fournissent des comparaisons de moyens multiples afin d’identifier les moyens particuliers qui sont différents.
ANOVA unidirectionnelle, bidirectionnelle et tripartite
L’ANOVA à un, deux et trois facteurs considère une conception complètement aléatoire pour une expérience.
ANOVA à un facteur
L’ANOVA à un facteur compare trois niveaux ou plus dans un facteur.
ANOVA bidirectionnelle
L’ANOVA bidirectionnelle est utile pour comparer l’effet de plusieurs niveaux de deux facteurs. L’ANOVA bidirectionnelle est une méthode appropriée pour analyser les principaux effets et interactions entre deux facteurs.
ANOVA à trois voies PRO
L’ANOVA à trois facteurs est pour les effets d’interaction entre trois variables indépendantes sur une variable dépendante continue (c.-à-d. S’il existe une interaction à trois facteurs).

Mesure répétée ANOVA PRO
La conception de mesures répétées est également appelée conception intra-sujet. Il a les mêmes sujets exécutés dans toutes les conditions.
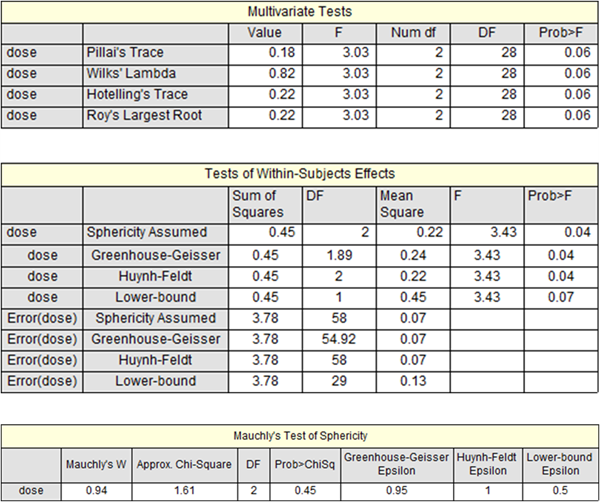
Les outils ANOVA à mesures répétées dans Origin considèrent trois conceptions possibles:
- Mesures répétées unidirectionnelles PRO
-
ANOVA avec un facteur de mesures répétées.
- Mesures répétées bidirectionnelles PRO
-
ANOVA avec deux facteurs de mesures répétées.
-
La conception mixte bidirectionnelle est également connue sous le nom de conception de parcelles séparées bidirectionnelles (SPANOVA). Il s’agit d’une ANOVA avec un facteur de mesures répétées et un facteur inter-groupes.
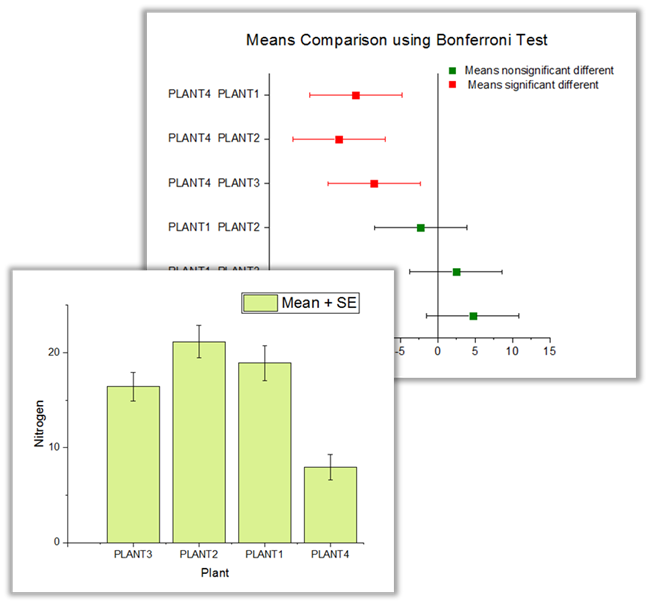
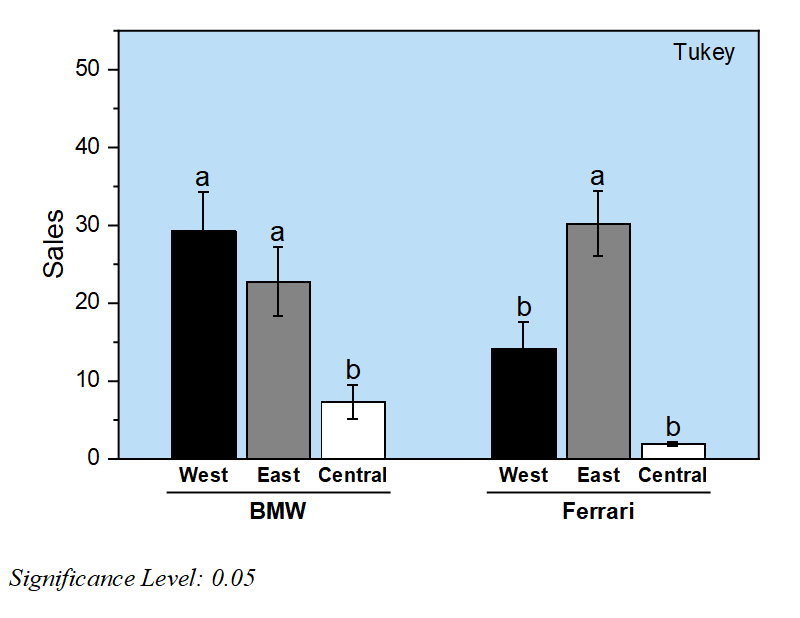
Comparaison des moyens / tests post-hoc
Les tests de comparaison de moyenne dans ANOVA, également connus sous le nom de tests Post Hoc, sont utiles pour effectuer des comparaisons supplémentaires de sous-ensembles de moyennes.
Les quatre outils ANOVA d’Origine, ANOVA à une et deux voies, ANOVA à mesures répétées un et deux voies, fournissent sept tests de comparaison des moyennes:
- Tukey
- Bonferroni
- Dunn-Sidak
- Fisher LSD
- Sheff ‘
- Holm-Bonferroni
- Holm-Sidak

Tests d’hypothèse paramétrique
Les tests d’hypothèse paramétrique sont fréquemment utilisés pour mesurer la qualité des paramètres d’échantillon ou pour tester si les estimations sur un paramètre donné sont égales pour deux échantillons.
Tests T pour les moyennes
Tests T sur les lignes PRO
|
|||
|
Tests de variance PRO
|
|||
|
Tests de proportion PRO
|
|||
|

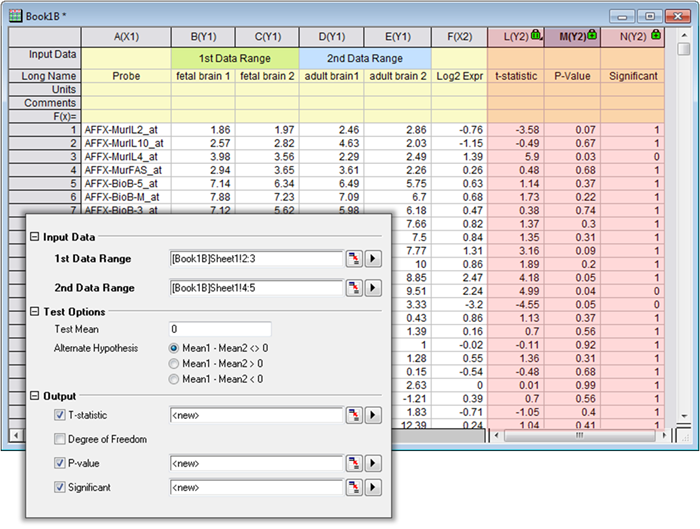
Tests non paramétriques PRO
Les tests non paramétriques sont utiles pour tester si les moyennes ou médianes des groupes sont réparties de la même manière entre les groupes. Dans ces types de tests, nous classons (ou classons dans l’ordre) chaque observation de notre ensemble de données. Les tests non paramétriques sont largement utilisés lorsque vous ne savez pas si vos données suivent une distribution normale ou si vous avez confirmé que vos données ne suivent pas une distribution normale. Pendant ce temps, les tests d’hypothèse sont des tests paramétriques basés sur l’hypothèse que la population suit une distribution normale avec un ensemble de paramètres.
Un échantillon
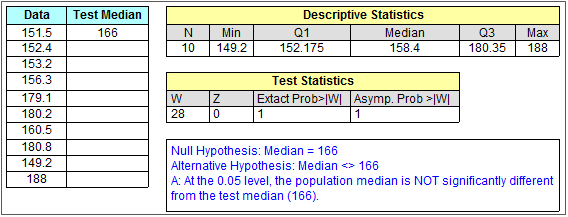
Test de classement signé Wilcoxon PRO
Le test de classement signé de Wilcoxon à un échantillon est une alternative non paramétrique au test t à un échantillon. Le test détermine si la médiane de l’échantillon est égale à une valeur spécifiée. Les données doivent être distribuées symétriquement par rapport à la médiane.

Deux échantillons 
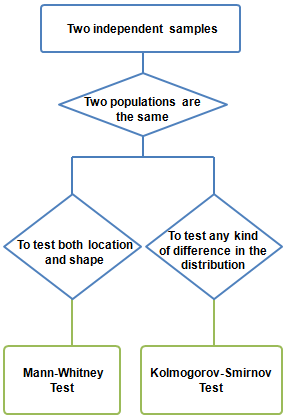
- Test de Kolmogorov-Smirnov PRO
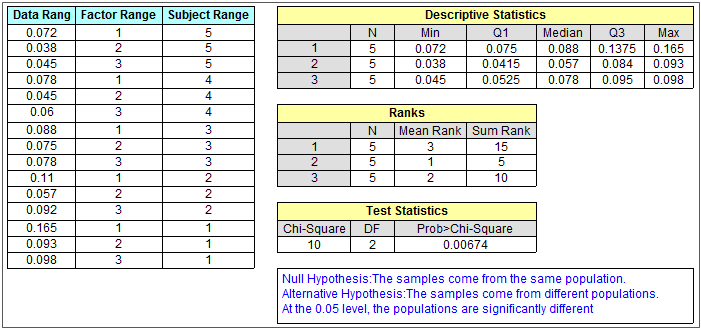
Plusieurs échantillons indépendants

Plusieurs échantillons associés
ANOVA de Friedman PRO
L’ANOVA de Friedman est une alternative non paramétrique à l’ANOVA à mesure répétée unidirectionnelle.
Friedman ANOVA peut être utilisé pour comparer des échantillons dépendants ou des observations répétées sur les mêmes sujets. Ainsi, le test est bien adapté aux conceptions de blocs aléatoires.
Analyse multivariée PRO
L’analyse multivariée est un ensemble de techniques utilisées pour analyser des données qui correspondent à plus d’une variable. L’objectif principal de cette analyse est d’étudier comment les variables sont liées les unes aux autres, et comment elles fonctionnent en combinaison pour distinguer plusieurs cas d’observations.
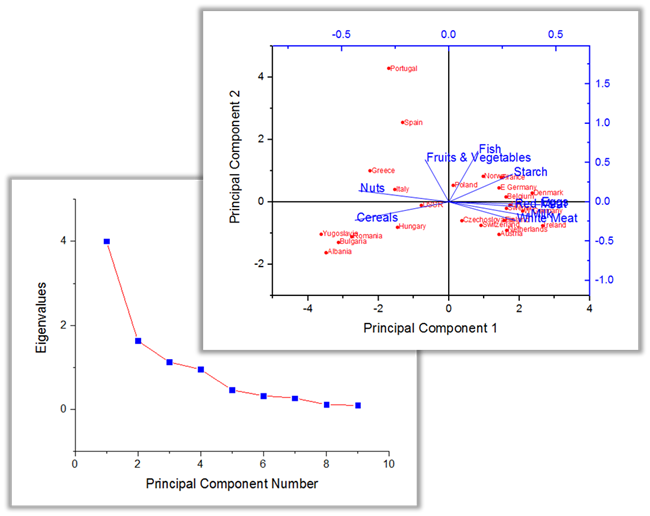
Analyse en composantes principales PRO
L’analyse en composantes principales (ACP) est utilisée pour expliquer la structure de variance-covariance d’un ensemble de variables au moyen de combinaisons linéaires de ces variables. L’ACP est donc souvent utilisée comme technique pour réduire la dimensionnalité.
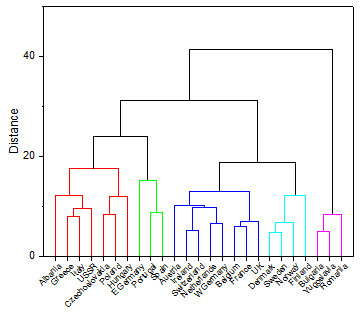
Analyse de cluster PRO
L’analyse par grappes est utilisée pour construire des groupes plus petits avec des propriétés similaires à partir d’un grand ensemble de données hétérogènes. Cette forme d’analyse est un moyen efficace de découvrir des relations au sein d’un grand nombre de variables ou d’observations.
PRO hiérarchique
Dans cette méthode, les éléments sont regroupés en grappes successivement plus grandes par certaines mesures de similitude ou de distance.
K-signifie PRO
Utilisez le clustering K-means pour classer les observations par K nombre de clusters.
C’est plus rapide que Hierarchical mais l’utilisateur doit connaître le centre de gravité des observations, ou au moins le nombre de groupes à regrouper.
Analyse discriminante PRO
L’analyse discriminante est utilisée pour distinguer des ensembles distincts d’observations et pour attribuer de nouvelles observations à des groupes préalablement définis.
Régression des moindres carrés partiels PRO
La régression des moindres carrés partiels (PLS) est utilisée pour construire des modèles prédictifs lorsqu’il existe de nombreux facteurs hautement colinéaires.
Il y a deux raisons principales pour utiliser PLS:
- Prédiction
PLS est le plus couramment utilisé pour construire un modèle prédictif lorsque les informations contenues dans un grand nombre de variables d’origine et qu’elles sont hautement colinéaires. - Interprétation
PLS peut être utilisé pour découvrir des caractéristiques importantes d’un grand ensemble de données. Il révèle souvent des relations qui étaient auparavant insoupçonnées, permettant ainsi des interprétations des données qui peuvent ne pas normalement résulter de l’examen des données.


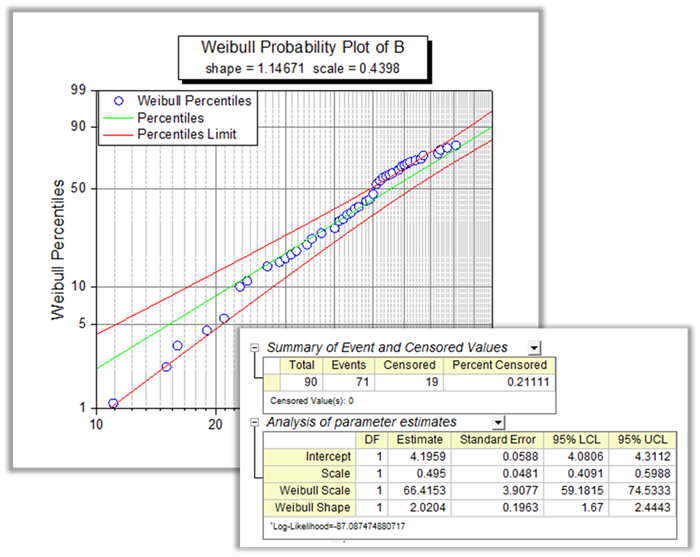
Analyse de survie PRO
L’analyse de survie est largement utilisée dans les biosciences pour quantifier la survie dans une population à l’étude. OriginPro comprend trois tests largement utilisés: l’estimateur Kaplan-Meier (limite de produit), le modèle de risques proportionnels de Cox et l’ajustement de Weibull.


Estimateur Kaplan-Meier PRO
L’estimateur Kaplan-Meier, un estimateur non paramétrique, utilise des méthodes de limite de produit pour estimer la fonction de survie à partir de données sur la durée de vie.
En plus d’estimer les fonctions de survie, l’estimateur de Kaplan-Meier dans Origin propose trois autres méthodes pour comparer la fonction de survie entre deux échantillons:
- Rang du journal
- Breslow
- Tarone-Ware
Modèle PRO de risque proportionnel de Cox
Le modèle des risques proportionnels, également appelé modèle de Cox, est une méthode semi-paramétrique classique. Il relie le moment d’un événement, généralement le décès ou l’échec, à un certain nombre de variables explicatives appelées covariables.
Weibull Fit PRO
L’ajustement de Weibull est une méthode de paramètres pour analyser la relation entre la fonction de survie et le temps de défaillance. Nous supposons que la fonction de survie suit une distribution de Weibull et ajuste le modèle avec une estimation du maximum de vraisemblance.
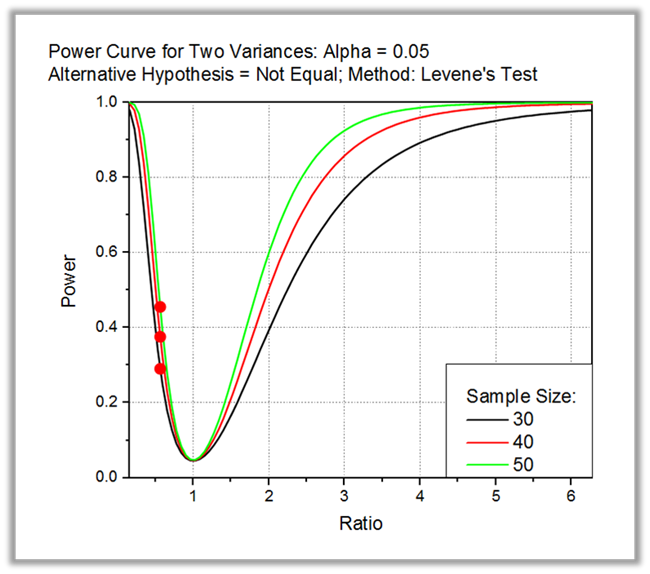
Puissance et taille d’échantillon PRO
L’analyse de la puissance et de la taille de l’échantillon est utile aux chercheurs pour concevoir leurs expériences. Il peut calculer la puissance de l’expérience pour une taille d’échantillon donnée, et peut également calculer la taille d’échantillon requise pour des valeurs de puissance données.
Les tests suivants sont disponibles:
|
||
ROC Curve PRO
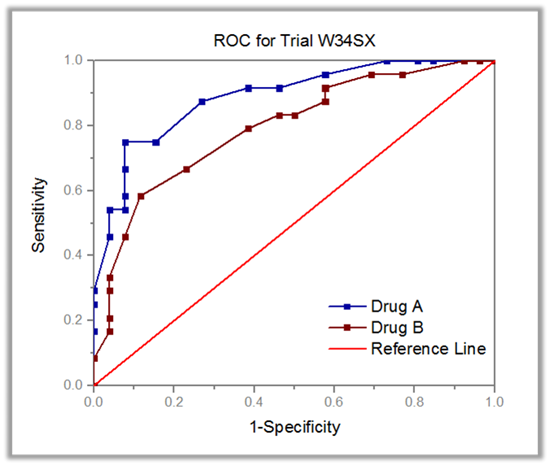
L’analyse de la courbe ROC (Receiver Operating Characteristic) est principalement utilisée pour les études diagnostiques en chimie clinique, pharmacologie et physiologie. Il a été largement accepté comme outil standard pour décrire et comparer la précision des tests de diagnostic.
Par exemple, vous pouvez utiliser l’analyse de courbe ROC pour tester un diagnostic afin de déterminer si un incident s’est produit ou comparer la précision de deux méthodes utilisées pour distinguer les cas malades des cas sains.
applications
Source de l’article

